
Etude de cas : le modèle UTOPIA
Présentation
Les données qui sont utilisées proviennent de l'ouvrage
réalisé lors du départ à la retraite de
Jacques-André Tschoumy, directeur de l'IRDP. Cet ouvrage voulait
répondre aux attentes d'un homme de la modernité, tourné
vers la complexité du monde en réalisant une mise en réseau
de réflexions. L'ouvrage qui a paru: Des utopies à
construire [COR 96], a pris une forme
originale dans son contenu et sa présentation. Un certain nombre
d'amis ou connaissance de J.-A. Tschoumy ont été sollicités
et ont accepté de jouer le jeu d'une écriture particulière,
chacun exprimant, sur un mode personnel ou scientifique, ce qu'évoquaient
pour lui quelques citations de Jacques-André Tschoumy et mettant
son propos en rapport avec d'autres auteurs, d'autres textes, d'autres
documents.
Les thèmes abordés étaient divers : la coordination scolaire, le droit à l'éducation, la citoyenneté européenne, la langue maternelle, l'éducation interculturelle et le plurilinguisme, la formation des enseignants, l'éducation aux médias et aux nouvelles technologies. Par ailleurs un comité de rédaction a sélectionné un certain nombre de concepts, regroupés en champs conceptuels (par exemple le champ c_altérité contient les mots-clés: autre, altérité, allophone), présents dans les textes afin de créer un index au sens classique du terme. Ce premier travail fournit les éléments de la structure de présentation écrite des textes, et rend possible une " navigation " intertextuelle par des renvois et un index de mots-clés.
L'ouvrage a paru sous forme d'un livre et d'un CD-ROM. Une version HTML publiée sur l'Internet (www.irdp.ch/utopies/utopies.htm) complète le panel des principaux supports disponibles à l'époque.
Ces données seront utilisées pour illustrer diverses façon de "réduire" un hypertexte (quotient, décomposition, etc.). Le noyau central des données servira également à discuter l'approche "a posteriori", c'est-à-dire la classification "automatiques" des unités d'information. On verra également sur cet exemple comment la structure d'un hypertexte se ramènera de proche en proche à une structure plus simple.
Organisation du document
Dans le cas particulier les concepts utilisés peuvent être classés en 7 catégories.
-
mot-clé: c'est la catégorie la plus spécifique de cet environnement. Elle est constituée de 80 mots-clés (appelés concepts dans le cas particulier!).
-
champ: cette catégorie sert au regroupement des mots-clés en 11 champs sémantiques.
-
auteur: les noms des 27 auteurs constituent une catégorie de concepts.
-
citation: chacune des 151 citations donnent lieu à un concept de la catégorie.
-
note: chacune des 13 notes donne également lieu à un concept de cette catégorie.
-
doc: cette catégorie est constituée de 9 concepts permettant de caractériser des documents particuliers: liste des auteurs (auteurs), bibliographie (biblio), introduction (intro), introductions à chacune des 6 parties de l'ouvrage (intro1 à intro6).
-
outil: cette catégorie comprend deux concepts, l'un permet de repérer la table des matières (tdm) et l'autre la liste des champs sémantiques (champs).
Chaque unité d'information possède un concept descripteur principal. Ce cas de figure simple est assez fréquent. La classification des concepts induit par conséquent une catégorisation naturelle sur les unités d'information (1).
|
Figure 1: Les flčches avec double pointe représentent des concepts multi-valués. Les types des concepts correspondent au code fléché suivant: mot-clé: flčche noire, mince ; champ: grise, large traitillée ; auteur: noire, large ; citation: grise, mince ; note: noire, large, traitillée ; doc: noire, mince, traitillée ; outil: grise, mince, traitillée. On notera que les flčches aller retour ne sont pas forcément du męme type (voir Auteurs, Texte d'auteur). Il n'y pas de retour sur tdm; il est pris en charge par le système de navigation. Ce schéma suggčre un rapprochement entre des types de concepts (liens) et des types d'unités d'information. |
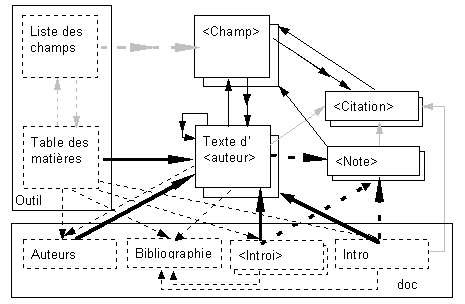
Le tableau 1 reprend les informations de la figure 1 sous forme symbolique. La définition des types d'unités d'information se fait à partir des types des descripteurs et des référents. Le symbolisme (standard) se lit de la manière suivante.
Tableau 1: Description
des types des unités d'information. Le symbolisme se lit de la
manière suivante. Dans la première ligne on lit qu'une
unité de type champ est définie par un descripteur de
type champ et des descripteurs de type mot-clé (au moins un,
ce qu'indique le signe +). Les référents sont une suite
de mots-clés (éventuellement aucun, ce qu'indique le signe
*). Le signe ? (2) indique la présence optionnelle
d'un élément du type considéré. Pour préciser
un concept particulier, on note son nom entre parenthèses après
le type.
| Type d'unité d'information | Type des concepts descripteur | Type des concepts référent |
| champ | champ & mot-cle+ | mot-cle* |
| texte d'auteur | auteur & mot-cle+ | doc(biblio, auteurs)? & note* & citation* & mot-cle+ |
| citation | citation & mot-cle* | mot-cle* |
| note | note | mot-cle* & citation* |
| doc | doc | mot-cle* & citation* & note* & doc? & auteur |
| outil | outil | outil & champ* & doc* & auteur* |
On peut préciser la caractéristique des unités d'information de type 'doc' et 'outil'.
doc: pour le document intro, les descripteurs sont de type: doc(intro) et les référents de type note, doc(biblio) et auteur(bouvier);
-
pour le document biblio, les descripteurs sont de type: doc(biblio) sans référent;
-
pour le document auteurs, les descripteurs sont de type: doc(auteurs) et auteur et les référents de type auteur (tous y aparaissent);
-
pour les documents introi les descripteurs sont de type: doc(introi) et les référents de type note, doc(biblio) et auteur;
outil: pour le document champs, les descripteurs sont de type: outil(champs) et les référents de type outil(tdm) et champ (tous apparaissent)
-
pour le document tdm, les descripteurs sont de type: outil(tdm) et les référents de type outil(champs), doc (tous apparaissent) et auteur (tous apparaissent).
Le tableau 2 donne les cardinaux des ensembles des unités d'information et des concepts pour l'hypertexte UTOPIA.
Le tableau 3 présente les coefficients liés aux concepts.
Dans le modèle UTOPIA, chaque mot-clé qui est descripteur d'une unitié d'information de type auteur ou citation ou champ est également référent. Donc Re* = Re et donc C = 1.
Il y a quelques exceptions lorsque que le mot-clé est utilisé dans une note. Re* est alors supérieur à Re.
En ce qui concerne les concepts de type auteur, la valeur de Re* vaut 2 pour les deux auteurs respectivement de l'introduction et de la conclusion (ils ne figurent pas dans les introductions des parties). Elle vaut 4 pour un auteur cité dans l'introduction.
Tableau 2: 1) Nombre
d'unités d'information, de concepts et de liaisons; 2)
valeurs moyennes des différents coefficients
| #U | #C | N | N* | |
| 213 | 294 | 631 | 735 |
| Rm | Rm* | Dm | Dm* | |
| 2.14 | 2.50 | 2.96 | 3.45 |
Tableau 3: Quelques
coefficients liés
aux concepts de l'hypertexte UTOPIA
| Types de concepts | Re | Re* | Rr | Rr* | C=Re*/Re |
| mot-clé (80) | 2 à 18 | Re | 0.00317 à 0.0285 | 0.00272 à 0.02585 | 1 |
| champ (11) | 1 | 1 | 0.00158 | 0.00136 | 1 |
| auteur (27) | 1 | 3 | 0.00158 | 0.00408 | Re* |
| citation (151) | 1 | 1 | 0.00158 | 0.00136 | 1 |
| note (13) | 1 | 1 | 0.00158 | 0.00136 | 1 |
| doc (9) | 1 | 1 18 biblio 28 auteur |
0.00158 | 0.00136 0.02449 0.03810 |
Re* |
| outil (2) | 1 | 1 | 0.00158 | 0.00136 | 1 |
Le tableau 4 donne les coefficients liés aux unités d'information. Ce tableau amène les remarques suivantes:
champ: La valeur de E est directement liée au nombre de mots-clés faisant partie du champ conceptuel;
texte d'auteur: des "profils" de textes sont donnés par la valeur de Di (nombre de mots-clés inclus +1) et E qui donne le rapport entre le nombre total de références (citations, notes, mots-clés, biblio) et Di. La valeur de Di donne donc l'étendue du texte par rapport à l'ensemble des thèmes; la synthèse, avec 40, atteint le maximum. La valeur de E donne le rapport entre les allusions externes et les thèmes traités (2,3 au maximum);
citation: chaque citation n'est utilisée qu'une seule fois (Di=1). En majorité Di* = 0, mais des valeurs de 1 ou 2 ne sont pas rares. Quelques citations ont des références et/ou des mots-clés;
note: Di*=0, sauf dans un cas où cette valeur vaut 8; une note a de nombreuses références.
Tableau 4: Quelques
coefficients liés
aux unités d'information de l'hypertexte UTOPIA.
| Type d'unité d'information | Di | Di* | Dr | Dr* | E=Di*/Di |
| champ (11) | 2 à 21 | Di-1 | 0.00317à 0.0332 | 0.0136 à 0.0272 | 0.5 à 0.95 |
| texte d'auteur (27) | 1 à 40 | 1 à 33 | 0.00158 à 0.0633 | 0.00136 à 0.0449 | 1 à 2.3 |
| citation (151) | 1 à 6 | 0 à 5 | 0.00158 à 0.00951 | 0 à 0.0068 | 0 à 0.83 |
| note (13) | 1 | 0 à 8 | 0.00158 | 0 à 0.0108 | Di* |
| doc (intro) | 1 | 2 | 0.00158 | 0.00272 | 2 |
| doc (biblio) | 1 | 0 | 0.00158 | 0 | 0 |
| doc (auteurs) | 1 | 27 | 0.00158 | 0.03673 | 27 |
| doc (introi) | 1 | 3-6 | 0.00158 | 0.00408 à 0.00816 | Di* |
| outil (tdm) | 1 | 37 | 0.00158 | 0.0503 | 37 |
| outil (champs) | 1 | 12 | 0.0018 | 0.0163 | 12 |
Le tableau 5 donne les valeurs des coefficients dérivés pour quelques unités d'information typiques. On rappelle que VS(u) donne le nombre d'unités d'informations "pointant" sur u sans compter la multiplicité alors que VM(u) tient compte de la multiplicité.
Les coefficients VS*(u) et VM*(u) font de même pour les référents.
On a r(u) = 1 - VS(u)/VM(u) et r*(u) = 1 - VS*(u)/VM*(u)
Les valeurs de VS*/VS (et VM*/VM) supérieures à 1 indiquent des unités d'information avec plus de référents que des descripteurs (unités productrices). Dans le cas des auteurs, cela dénote des articles avec des notes et des illustrations.
Des valeurs de r*(u) et r(u) faibles correspondent à des unités dont les concepts référents (resp. descripteurs) ne sont pas descripteurs (resp. référents) communs de beaucoup d'unités d'information. C'est en particulier le cas de la table des matières dont tous les concepts sont liés univoquement à un seul document, tous différents.
Les valeurs de r*(u) et r(u) sont sensiblement égales vu la construction de l'hypertexte.
Dans le cas des auteurs, plus le nombre de mots-clés utilisés dans le document est grand et plus les valeurs de r*(u) et r(u) sont élevées dans la mesure où ils indexeront un nombre commun plus importants de documents. En particulier, ces valeurs sont maximales pour le document cardi qui procède à la synthèse des autres articles (cela prouve donc que ce document est bien une synthèse).
Tableau 5: Multiplicité,
rendement et rapports associés de quelques unités d'information
| Unité d'inf. | VS | VS* | VM | VM* | VS*/VS | VM*/VM | r(u) | r*(u) |
| tdm | 1 | 37 | 1 | 37 | 37 | 37 | 0 | 0 |
| bronc | 53 | 63 | 123 | 132 | 1.19 | 1.07 | 0.57 | 0.52 |
| cardi | 76 | 75 | 245 | 239 | 0.99 | 0.98 | 0.69 | 0.69 |
| gred | 12 | 10 | 13 | 11 | 0.83 | 0.84 | 0.08 | 0.09 |
| cite1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | x |
| cite2 | 16 | 16 | 20 | 19 | 1 | 0.95 | 0.2 | 0.16 |
| cite3 | 8 | 8 | 9 | 8 | 1 | 0.89 | 0.11 | 0 |
| note1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | x |
| note2 | 1 | 35 | 1 | 62 | 35 | 62 | 0 | 0.44 |
| intro6 | 1 | 6 | 1 | 6 | 6 | 6 | 0 | 0 |
| biblio | 18 | 0 | 18 | 0 | 0 | 0 | 0 | x |
| auteurs | 28 | 27 | 28 | 27 | 0.96 | 0.96 | 0 | 0 |
| c_europe | 15 | 14 | 15 | 14 | 0.93 | 0.93 | 0 | 0 |
| c_alterite | 14 | 13 | 15 | 14 | 0.93 | 0.93 | 0.07 | 0.07 |
| c_echange | 31 | 29 | 67 | 65 | 0.94 | 0.97 | 0.54 | 0.55 |
Analyse par décomposition (juxtaposition)
Le tableau 6 présente les valeurs moyennes pour 4 sous-hypertextes dont UTOPIA est la juxtaposition (cette décomposition arbitraire sera justifiée ultérieurement). Il permet de vérifier des relations II présentées dans un autre document. En utilisant une notation de décomposition:
![]()
avec:
![]() : hypertexte
constitué des unités d'information champ, texte d'auteur,
citation (en principe les unités d'information qui peuvent être
référencées par des mots-clés);
: hypertexte
constitué des unités d'information champ, texte d'auteur,
citation (en principe les unités d'information qui peuvent être
référencées par des mots-clés);
![]() :hypertexte
contenant les notes ;
:hypertexte
contenant les notes ;
![]() : ensemble
des documents intermédiaires (bibliographie, introduction, etc.);
: ensemble
des documents intermédiaires (bibliographie, introduction, etc.);
![]() : outils
de navigation, table des matière et liste des champs.
: outils
de navigation, table des matière et liste des champs.
A noter que cette décomposition est une décomposition a priori. En effet, il n'est pas dit, entre autres, que toutes les citations contiennent effectivement des mots-clés.
Tableau 6 : coefficients pour
différents sous-hypertextes
| #U | N | N* | Dm | Dm* | #C | Rm | Rm* | |
| H|mot-cle | 189 | 607 | 618 | 3.212 | 3.270 | 291 | 2.086 | 2.124 |
| H|note | 13 | 13 | 8 | 1 | 0.615 | 244 | 0.053 | 0.033 |
| H|doc | 9 | 9 | 59 | 1 | 6.556 | 280 | 0.032 | 0.211 |
| H|outil | 2 | 2 | 49 | 1 | 24.5 | 49 | 0.041 | 1 |
| H | 213 | 631 | 734 | 2.962 | 3.451 | 293 | 2.146 | 2.5 |
Analyse par quotient
La figure 1, peut également être lue au premier degré. C'est-à-dire que l'on peut considérer que chaque concept s'identifie à sa classe. Il y aura donc dans ce cas particulier, 7 concepts. Le résultat de cette opération est désigné par l'hypertexte "quotient ".
Le tableau 7 donne quelques coefficients de ce nouvel hypertexte "quotient".
Tableau 7:Coefficients de l'hypertexte quotient
| #U | #C | N | N* | |
| 213 | 11 | 316 | 186 |
| Type d'unité d'information | Di | Di* | Dr | Dr* | E=Di*/Di |
| champ (11) | 2 | 1 | 0.00317à 0.0332 | 0.0136 à 0.0272 | 0.5 à 0.95 |
| texte d'auteur (27) | 2 (1 cas avec 1) | 2 à 4 (1 cas avec 2) | 0.00158 à 0.0633 | 0.00136 à 0.0449 | 1 à 2.3 |
| citation (151) | 1 ou 2 (69) | 0 ou 1 | 0.00158 à 0.00951 | 0 à 0.0068 | 0 à 0.83 |
| note (13) | 1 | 0 à 2 | 0.00158 | 0 à 0.0108 | Di* |
| doc (intro) | 1 | 3 | 0.00158 | 0.00272 | 2 |
| doc (biblio) | 1 | 0 | 0.00158 | 0 | 0 |
| doc (auteurs) | 1 | 1 | 0.00158 | 0.03673 | 27 |
| doc (introi) | 1 | 1 ou 2 ou 3 | 0.00158 | 0.00408 à 0.00816 | Di* |
| outil (tdm) | 1 | 3 | 0.00158 | 0.0503 | 37 |
| outil (champs) | 1 | 2 | 0.0018 | 0.0163 | 12 |
La formule I devient:
![]()
Pour une décomposition de type II (décomposition en éléments maximaux), on considère le tableau 8 qui reprend la disposition d'une figure générale mais en faisant figurer les types des concepts et des types d'unités d'information au lieu des concepts et des unités d'information. d est donnée par la partie supérieure et d* par la partie inférieure. Ce schéma correspond à la décomposition:
![]()
Ce tableau permet de reprendre le problème de la classification a priori ou a posteriori. L'étoile (*) permet de signaler qu'il peut y avoir des unités d'information du type a priori qui ne possèdent pas le concept associé. La double étoile (**) indique que la plupart des unités d'information de la catégorie ne possède pas le concept associé. Une classification automatique, a posteriori, créerait donc des groupes supplémentaires à moins qu'une certaine "marge d'erreur" ne soit autorisée. Une classification a posteriori aurait pu faire figurer la préface dans la classe des "doc" plutôt dans celle des auteurs. Le même problème se pose à propos des textes sans référence bibliographique.
Tableau 8 : décomposition d'un hypertexte en éléments maximaux
| types de concept | |||||||
| mot-cle | x | x* | x** | ||||
| champ | x | ||||||
| auteur | x | ||||||
| citation | x | ||||||
| note | x | ||||||
| doc | x | ||||||
| outil | x | ||||||
| champ (11) |
auteur (27) |
citation (151) |
note (13) |
doc (9) |
outil (2) |
types d'ui | |
| outil | x | ||||||
| doc | x | x | x | ||||
| note | x* | x* | |||||
| citation | x* | x** | x* | ||||
| auteur | x | x | |||||
| champ | x | ||||||
| mot-cle | x | x* | x** | x** | x* |
Le tableau 9 montre une autre décomposition de l'hypertexte en regroupant champ, auteur et citation. Dans une classification a priori la décomposition en éléments maximaux est :
![]()
A posteriori, cette égalité n'est qu'approximative.
Il faudrait ajouter deux composantes: les unités d'informations
de type t5 et t6, avec t5 = : H({auteur},{doc}) et t6 = H({citation},![]() )
)
Dans le schéma, la parenthèse, indique un concept qui peut être en relation pour quelques unités d'information présentes.
On notera que H|note et H|outil sont deux hypertextes à la fois juxtaposés et superposés. Ils sont déconnectés.
Tableau 9 : décomposition
minimale de l'hypertexte
| types de concept | 1 | 2 | 3 | 4 | 5 | 6 | |
| mot-cle | x | ||||||
| champ | (x) | ||||||
| auteur | (x) | x | |||||
| citation | (x) | x | |||||
| note | x | ||||||
| doc | x | ||||||
| outil | x | ||||||
| mot-cle | note | doc | outil | t5 | t6 | types d'ui | |
| outil | x | ||||||
| doc | (x) | x | x | x | |||
| note | (x) | x* | |||||
| citation | (x) | x** | x* | ||||
| auteur | x | x | |||||
| champ | x | ||||||
| mot-cle | x* | x** | x* |
Structure générale
En utilisant la matrice du graphe, on trouve 213 valeurs propres du Laplacien "tronqué" à 0.1 et dichotomisé.
Ces valeurs propres (entre parenthèse leur multiplicité) sont tout d'abord:
0 (127) , 1 (3), 3 (3), 5 (2), 6, 7 (2), 8 (2) ;
puis 73 valeurs sont non entières variant de 1.155 à 20.217
Cet hypertexte contient donc beaucoup d'unités d'information assez isolées (les notes et les citations). Il reste à mettre en évidence de façon automatisée les unités d'informations "atypiques".
Notes
1) Il s'agit ici d'un typage a priori des unités d'information. Un typage a posteriori doit introduire quelques modifications ŕ ce schéma idéal.
2) L'utilisation de ce signe est principalement lié ŕ une description a priori. Dans une recherche de structure a posteriori, il n'a évidemment aucun sens !