
A propos de typage d'unités d'information
Position du problème
La classification des hypertextes pose principalement quatre problèmes: celui de l'organisation des concepts, celui de la structure générale de l'hypertexte (en terme de théorie des graphes par exemple), celui de la classification des unités d'information, et celui de la relation entre les deux problèmes précédents.
Le premier problème peut s'aborder de diverses manières. Tout d'abord on peut envisager un regroupement des concepts en diverses catégories construites par "subsumation" ou arbitrairement.
L'analyse en "cluster" offre une autre possibilité de procéder à des regroupements de concept de façon automatique. Dans ce cas, deux concepts font parties du même groupe, s'ils ont des descripteurs et/ou des réfèrents de "presque" les mêmes unités d'information. Cette approche ne va pas sans poser quelques questions, au niveau ontologique (à ne pas confondre ce type de regroupement par distance et les opérations de réductions "vectorielles" telle que la méthode LSI), et par rapport aux typages ultérieurs des unités d'information.
Introduire des types de concepts est un premier pas modeste d'une approche par "ontologies" ou par réseau sémantique qui précise diverses "propriétés" des liens: fonction (par exemple: note), type de cible, etc.
A noter qu'au typage des concepts correspond le typage des liens de l'hypertexte.
On trouve un exemple de cette notion dans la présentation de
UTOPIA.
Le deuxième problème est abordé dans d'autres documents [1].
En ce qui concerne le troisième problème, celui du type des unités d'information certaines approches [LUC 96] introduisent les hypertextes en terme de classes et d'objets. Chaque unités d'information est une instance d'une classe définie a priori. Le problème de la classification revient donc à un problème d'analyse a priori.
La classification peut aussi se faire "a posteriori": connaissant une certain nombre d'unités d'information (des objets) le problème est de définir les classes d'objets.
Le quatrième problème concerne le lien entre les aspects locaux (structures des unités d'information) et globaux (structure de l'hypertexte). Ces aspects sont liés dans la mesure où une identification de certaines unités d'informations (aspect local), simplifie la mise en évidence de la structure globale. La structure d'un arbre est plus facile à appréhender lorsqu'il est dépouillé de ses feuilles !
Du point de vue matriciel, l'aspect local revient à identifier (et regrouper, voire coaguler) des lignes et des colonnes de même profil. L'aspect global est lié à une structure plus profonde.
A propos du typage des concepts
Un typage des concepts est donné par un ensemble de parties de C. Un cas particulier de typage est celui où il n'y a qu'un seul concept de chaque type. Un typage sera désigné par un ensemble: T = {t1, t2, ..., tp} sous-ensemble des parties de C. En principe, et ce sera toujours le cas ici, cet ensemble constitue une partition de C.H | t est la restriction de l'hypertexte aux concepts de t.
On a la formule triviale:
(I) H = ![]() H | t (sommation-superposition sur T)
H | t (sommation-superposition sur T)
Hypertexte quotient
Etant donné un type T on peut considérer l'hypertexte quotient: H/T où l'ensemble des concepts est remplacé par l'ensemble des classes avec les relations déduites de façon canonique. L'hypertexte quotient correspond à une version de l'hypertexte avec une définition plus "grossière".
Regroupement d'unités d'information
On rappelle qu'une unité d'information est donnée par un double vecteur, une partie du vecteur représentant des concepts (ou des types de concepts) "descripteur" et l'autre des "référents". On s'en tient ici à la marque de présence/absence sans pondération (une unité d'information devient un vecteur de 0 et de 1).
Diverses approches sont possibles (2) si l'on veut retrouver des unités semblables:
-
Approche par métrique: il est possible de procéder à une analyse cluster globale (descripteurs et référents) ou une double analyse cluster en prenant une distance adéquate, par exemple le pourcentage de désaccords. On notera qu'en identifiant g groupes, on réduit le nombre de concepts utiles à log g (log en base 2). Cette remarque montre qu'il n'est pas possible de procéder à la fois à une analyse cluster sur les concepts et sur les unités d'information (voir aussi le problème de la double décomposition).
-
Approche vectorielle: on peut constater que deux unités disjointes (ne possèdant pas de descripteurs communs) sont données par des vecteurs orthogonaux. Cette approche, sauf dans des cas particulier, invite à procéder à des recherches d'axes dont il est difficile ultérieurement de trouver une signification.
-
Approche par entropie de groupe: cette approche est suggérée par Watanabe. Le problème est de trouver un algorithme efficace.
-
Approche hiérarchique ensembliste: cette approche considère le "lattice" constitué par les unités d'informations (3) et tente d'en déterminer les "filières" importantes. Le problème est également de trouver un algorithme efficace et de "critères d'arrêt" judicieux (à voir homologie simpliciale ensembliste).
-
Usage de la "reconstructability analysis": cette théorie étend la notion de facteur des analyses factorielles classiques à des cas avec variables nominales (cette piste sera poursuivie dans un autre document).
Dns la pratique, le nombre de concepts peut être élevé et la classification des unités d'information ne peut se réaliser qu'après un regroupement des concepts.
Par exemple: à partir des types de concepts tels que note, auteur, etc. on peut dégager le type d'unité d'information "article". A partir de types de concepts donnés par un science: physique, chimie, etc. on peut dégager les unités d'information en biologie (descripteur) faisant appel à des notions de chimie et physique.
Pour chaque unité d'information u, on définit: T(u) l'ensemble des descripteurs de u et T*(u) l'ensemble des référents de u.
Si P et P' sont deux parties de C (ou de T), on note U(P, P') les unités d'informations u telles que T(u) contient P et T*(u) est compris dans P'.
Cette définition est motivée par le fait que, étant donné des descripteurs et des référents, les unités d'information intéressantes sont celles qui sont décrites par les concepts souhaités en ne faisant pas appel à plus d'informations complémentaires.
Cela permet de constituer des familles d'unités d'information.
(P, P') ![]() U(P, P')
est une application qui à chaque couple de parties de
C fait correspondre une partie de U
(fig 1). Le problème est de trouver une famille de couples (P,
P') qui fournit une décomposition
"intéressante" de U.
U(P, P')
est une application qui à chaque couple de parties de
C fait correspondre une partie de U
(fig 1). Le problème est de trouver une famille de couples (P,
P') qui fournit une décomposition
"intéressante" de U.
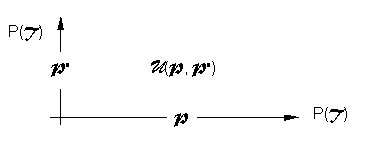
Figure 1: A chaque couple (P,
P') de parties de C
correspond une partie de U.
On a les propriétés:
![]()
Les ensembles U(P, P') s'organisent en filière. Le problème est de trouver un niveau de "coupure" pour chaque filière, donc une famille de couples (P, P') dont les ensembles U(P, P') correspondant présentent une certaine utilité et qui fournissent partition de U .
On note H(P, P') l'hypertexte dont les unités d'informations sont U(P, P').
Si T = {t1, t2, ..., tp}, un cas particulier est donné par celui où la famille U({ti}, T) (avec ti les types de concepts) conduit à une partition de l'ensemble des unités d'information. Dans ce cas, en notant ti le type donné par le couple ({ti}, T), on peut écrire la relation (décomposition en éléments maximaux):
(II) H = ![]() H|ti (sommation-juxtaposition
sur T)
H|ti (sommation-juxtaposition
sur T)
Avec H|ti = H({ti}, T).
Les unités d'informations de type: U(P, P) peuvent aussi constituer des cas intéressants.
A noter que si une classification des unités d'information a été effectuées, un typage des concepts induit une nouvelle classification moins fine que la précédente. Un mauvais typage peut rendre la classification inintéressante.
Notes
1) Le document structure d'un hypertexte sous forme matricielle présente une approche probabiliste de la structure globale d'un l'hypertexte, quant à hypertextes et théorie des graphes, il rappelle de quelques résultats de la théorie des graphes et leur application au graphe de l'hypertexte.
2) Pour une approche naïve voir Typage et classification des unités d'information de Utopia.
3) Dans ce cas les unités d'information sont liées les unes aux autres par leur "ressemblance". Attention: ne pas confondre ce lattice avec le graphe de circulation dans l'hypertexte.