
Décomposition en valeurs singulières et analyse de contenu
Présentation
Le but de cette brève note est de mesurer l'apport d'une décomposition en valeurs singulières (SVD) par rapport à une analyse cluster en prenant pour cas pratique une analyse de contenu.
Situation et jeu de données
Le problème est de procéder à une classification de documents chacun étant caractérisé par un certain nombre de "concepts".
Dans cette situation, il est possible de classer les documents à partir des concepts ou les concepts à partir des documents. La question qui se pose est de savoir s'il est possible de trouver un procédé qui permet de mener parallèlement ces deux regroupements. Ce travail explore la piste du "SVD".
Du point de vue des données on possède donc une matrice qui représente une relation "mot-document". Pour fixer les idées, dans notre cas les lignes de la matrice représenteront des documents. Chaque valeur (0 ou 1) notant la présence ou l'absence du concept dans le document. Les colonnes de la matrice représentent les "concepts". Chaque valeur notant la présence ou non du concept dans le document.
Concrètement un jeu de données a été obtenu à partir d'une analyse de la presse sur le sujet de l'usage d'Internet dans la formation (Berney, Pochon, 2000). Ces données contenaient 103 documents et 244 concepts.
Questions
Ces analyses permettent de se poser 3 questions qui rejoignent les préoccupations développées dans le cadre de l'analyse de documents hypertextuels :
-
De quelle manière ces deux analyses, qui ne sont pas indépendantes l'une de l'autre, sont-elles reliées?
-
Est-il possible d'établir un algorithme qui les mènerait conjointement?
-
Quel peut être l'apport de la méthode SVD dans cette situation?
1) Analyses conjointes
Deux analyses cluster "classiques" ont été conduites qui ont permis de regrouper d'une part les articles en 10 groupes et d'autres part les concepts "descripteurs" en 17 concepts génériques.
Les deux analyses ont été mis en correspondance et la compatibilité entre les deux analyses a pu être vérifiée, ainsi que le montre le tableau 1. (problème de la double décomposition).
Tableau 1 : La première ligne donne le numéro du concept. La deuxième ligne du tableau donne le nombre d'unités conceptuelles dans chacun des groupes. La première colonne énumère la liste des groupes d'articles avec, entre parenthèses, le nombre d'articles intégrant le groupe. Au croisement de la ligne i et de la colonne j se trouve le nombre de descripteurs du groupe j décrivant des articles du groupe i. En grisé on trouve les cas où tous les articles du groupe i sont liés à au moins un descripteur de j.
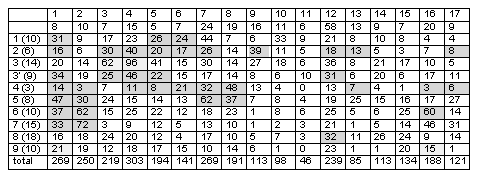
Tableau 2 : Par regroupement en plus grandes unités on voit que les descripteurs «abstraits» permettent de décrire les groupes d’articles. Le 1 signifie que tous les articles du groupe possède un descripteur abstrait de la catégorie donnée .
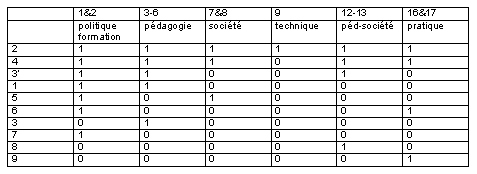
Note: Une analyse cluster menée sur les documents paramétrés par le regoupement des concepts" ne mène pas au même résultat:
2) Algorithme
L'algorithme qui permettrait de mener la diagonalisation conjointe semble exister sous la dénomination de "block seriation" (Lelu, 1991). Cette piste reste à explorer.
3) Usage de SVD
De façon un peu naîve, nous avions pensé qu'une analyse factorielle (analyse des correspondances ou à composantes principales voire avec rotations) éventuellement un peu généralisée, pourrait résoudre ce problème de "double clustering". Notre constat est que tout d'abord les calculs sont difficiles à mener avec des matrices très creuses (nombreuses valeurs nulles). L'algorithme de SVD est lui par contre très robuste de ce point de vue et pourrait offrir une piste.
Toutefois, l'expérience (à défaut de réflexion!) montre que les axes extraits par ces analyses sont quasiment ininterprétables (ce point est également mentionné par Lelu, 1991). C'est-à-dire que la fabrication de combinaisons linéaires de concepts suit une toute autre logique qu'un regroupement avec établissement de hiérarchies (subsumation).
Par contre, on observe en passant que la décomposition SVD (singular value decomposition, voir Will, 1999) permet de dégager des concepts à partir d'éléments plus primitifs (les mots). Cette observation est à la base de l'utilisation de la décomposition SVD dans l'indexage sémantique des documents (LSI, voir Berry & al, 1995).
Plus concrètement, M représente une matrice "documents x mots" (chaque ligne est un vecteur document, chaque colonne donne la présence d'un mot dans un document). On suppose cette matrice de dimension d x m. Cette matrice est décomposée par une SVD en un produit de 3 matrices dont la matrice centrale (D) est diagonale (entre parenthèses figurent les dimensions de ces matrices):
M (d x m) = R (d x d) D (d x m) U (m x m)
U est une matrice mot x mot: chaque colonne de cette matrice représente une combinaison linéaire de mots.
Ensuite on considère D' obtenue à partir de D en remplaçant par 0 les valeurs "faibles" de la diagonale:
M' = R D' U représente une "bonne" approximation de M.
On suppose que D' contient c valeurs non nulles. A noter alors que sans modifier le résultat on a M' (d x m) = R' (d x c) D' (c x c) U' (c x m) où U' est la matrice constituée par les c premières lignes de U et R' est la matrice constituée par les c premières colonnes de R.
Finalement M''(d x c) = R'(d x c) D'(c x c) U''(c x c) où U'' est la matrice constituée par les c premières colonnes de U'.
Chacune des colonnes de U'' représente un "concept" et M'' est la matrice "documents x concepts" associée.
Pour conclure
En définitive, nous avons redécouvert (!) la possibilité d'utiliser la méthode SVD à fin d'indexage (mise en évidence de "concepts"). Un certain nombre de questions sont relatives à cet usage:
Problème de lexique: dans un tel processus comment tenir compte des déclinaisons d'un même mot (pluriel, conjugaison, etc.)
Problème de dimension: le procédé ne permet pas vraisemblablement d'indexer un nombre illimité de documents. Faut-il procéder par échantillonnage ? (voir aussi le point suivant).
Problème d'ajout: un nouveau document peut facilement être intégré à un corpus par indexation (on lui applique des "concepts" préétablis). Lorsqu'il s'agit d'ajouter beaucoup de documents, il faut probablement procéder à une refonte complète de l'indexation (cette opération est parfois connue sous le terme de recuit). Existe-t-il des résultats sur l'effet, au niveau des concepts, de la fusion de deux corpus de documents.
Références
Berney, J. & Pochon, L.-O. (2000). Internet à l'école: analyse du discours à travers la presse. Neuchâtel: Institut de recherches et de documentation pédagogique. (00.5) (résumé).
Berry, M.W., Dumais, S.T. & Shippy, A.T. (1995). A case study of latent semantic indexing. Knoxville: University of Tennessee, Computer science department.
Latent Semantic Indexing (LSI) site web
Lelu, A. (1991). From data analysis zo neural networks: new prospects for efficient browsing through databases. Journal of Information Science 1991(17), 1-12
Will, T. (1999). Introduction to the Singular Value Decomposition. Davidson College (page web)