
Deux limites de l'analyse cluster et "ugly duckling" problem
La situation
Dans certains cas les procédures de classification ne donnent pas satisfaction. Plusieurs raisons peuvent être invoquées.
Les deux problèmes traités ici sont liés à des situations déséquilibrées. Le premier est mentionné dans l'ouvrage de Watanabe (1969). Il est lié à une généralisation du "ugly duckling problem", le nombre de concepts ("prédicat") est grand par rapport au nombre d'observations (documents).
Le deuxième problème a un fond similaire. Dans ce cas le nombre d'observations est grand par rapport au nombre de prédicats.
Etudes des cas
Cas 1
La situation est représentée par la table suivante avec 4 objets et 8 prédicats (et non 16 comme dans le cas standard du "vilain petit canard"):
| No | P1 | P2 | P3 | P4 | P5 | P6 | P7 | P8 |
| O1 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 |
| O2 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 |
| O3 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 0 |
| O4 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 |
On s'aperçoit que tous les objets sont à distance 4 les un des autres. Une analyse cluster est donc incapable de distinguer des groupes. D'autres méthodes sont disponibles.
Cas 2
La situation est plus banale. On suppose donné n objets que l'on peut décrire par l'absence ou la présence de m propriétés. Un cas extrême apparait lorsque n = 2m et que tous les objets sont distincts (tous les pattern possibles apparaissent). En prenant une des distances équivalentes à la distance euclidienne, il apparaît que pour tout objet O, il existe toujours un objet O' à distance 1. De proche en proche tous les objets sont donc du même groupe.
La question est de savoir comment, en pratique, une telle situation est traitée dans les analyses cluster automatiques.
Un jeu de 16 objets caractérisés par 4 variables a été envisagé. Pour l'objet numéro n, les variables sont les valeurs des digits de la décomposition du nombre n-1 en base deux.
| No | O1 | O2 | O3 | O4 | O5 | O6 | O7 | O8 | O9 | O10 | O11 | O12 | O13 | O14 | O15 | O16 |
| P1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| P2 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 |
| P3 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 |
| P4 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 |
Le logiciel utilisé est STATISTICA. Dans tous les cas la distance euclidienne est utilisée. Par contre, on utilise différents algorithmes d'aggrégation. Comme on peut s'y attendre un seul groupe est mis en évidence avec quelques nuances toutefois:
Liaisons simples
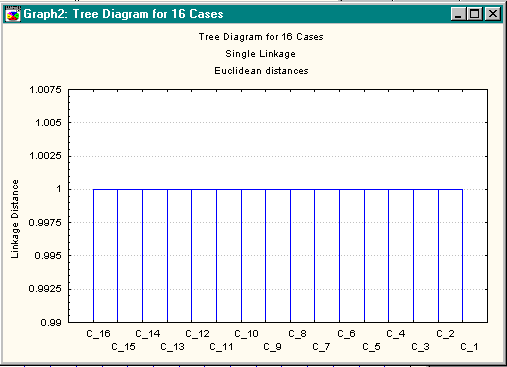
Dans ce cas, comme attendu, un seul groupe est créé.
Liaisons complètes
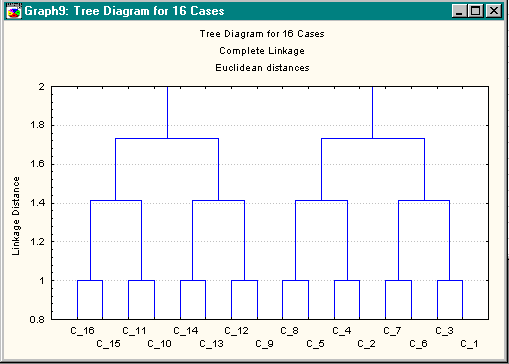
Dans ce cas, on trouve une hiérarchie qui reproduit la structure de la numération en base deux. Dans un tel cas pour trouver le niveau adéquat, il faut comparer les résultats obtenus pour diverses organisations des objets (les "clusters" doivent rester invariants sous permutation des données). Pour des raisons évidentes de symétrie, d'autres tris nous obligent à ne considérer qu'un seul groupe. La méthode d'agrégation de Ward conduit à un résultat semblable.
Conclusion
Cette brève note montre clairement l'effet du vilain petit canard mentionné par Watanabe. Elle suggère également l'étude du rapport des valeurs idéales entre nombre d'objets et nombre de groupes.
Référence
Watanabe, S. (1969). Knowing and Guessing. A quantitative study of inference information. New-York: John Wiley and Sons.