|
Avez-vous remarqué combien tout
est
"méta" sur Internet par les temps qui courent?
Guy Teasdale, Métachronique XML |
La LettreNo 9, mars 2002Feuille de réflexion et d'information sur l'EAO |
![]()
Créer des documents pédagogiques électroniques, portables et pérennes: pas une mince affaire
Combien de fois faudra-t-il recommencer à coder les mêmes informations ? C'est vraisemblablement la question que se posent les collègues ayant une certaine expérience de l'utilisation de l'ordinateur dans l'enseignement. Après les multiples langages de programmation, systèmes auteur, voici venir le temps des navigateurs et du HTML.
Est-ce une illusion ? Il apparaît que l'âge mûr de l'édition de documents pédagogiques est arrivé avec, à la fois, une réflexion sur les standards et les formats. Il manque encore une réelle prise en compte de la "culture" des développeurs potentiels, problématique qui fera l'objet d'une prochaine lettre.
Introduction
Lorsqu'il s'agit de communiquer à travers les réseaux ou de partager des ressources, trois niveaux sont à considérer dans l'élaboration des documents. Celui de la nature des informations et leur organisation (niveau sémantique général), celui du codage de ces informations (niveau syntaxique) et celui de la mise en forme (niveau présentation).
Dans le domaine de l'information et de l'éducation, dans ce que l'on appelle le "e-learning", le niveau sémantique est représenté par les standards qui se mettent en place et qui définissent différents types de documents pédagogiques.
Le deuxième niveau est celui des formats qui, c'est bien connu, sont en très grand nombre. Cette brève note s'attachera à un format particulier, XML, qui permet de décrire de multiples situations ou, pour le moins, de servir de fédérateur entre différents formats spécialisés (son, image).
Quant au troisième niveau, il est souvent directement lié au niveau précédent. Si l'on souhaite garder une ligne la plus ouverte possible, un simple navigateur web constituera la plateforme de visualisation. Mais ce niveau n'est pas fondamental pour notre propos puisque le but poursuivi est de rendre le codage des données et leur organisation indépendants des moyens de présentations, ce qui offre des garanties de pérennités.
Les standards
Différents standards existent, ils sont présentés dans l'annexe 1. Chaque fois, on peut constater que ce sont des travaux d'envergure liés à des communautés d'une certaine importance. Dans des travaux plus restreints, il est possible de s'en inspirer ou de ne les prendre en compte qu'en partie. Les standards concernent les contenus, l'architecture du système, c'est-à-dire une certaine façon de considérer l'instruction et les profils des apprenants. Cela rejoint les travaux traditionnels concernant les ITS (intelligent tutoring systems) avec les experts du domaine, de la pédagogie et du modèle de l'étudiant.
Deux notions associées aux standards apparaissent souvent:
Métadonnées (metadata): c'est la
manière de nommer des données qui décrivent les
données. Elles contiennent un dictionnaire des données
(noms, unités, critères de validation, etc.), la
description des traitements subis par les données, etc. Selon
l'approche adoptée, les métadonnées peuvent
comprendre une ontologie.
Ontologie: une ontologie est une
spécification
d'une conceptualisation, c'est-à-dire la description des
relations entre différents concepts. Un thésaurus est une
ontologie primitive. Cette notion provient du domaine de l'intelligence
artificielle (www-ksl.stanford.edu/kst/what-is-an-ontology.html).
A distinguer de l'ontologie utilisée en philosophie où ce
terme se réfère à l'existence. Une groupe de
travail du W3C est dédié à ce sujet (www.w3.org/2001/sw/WebOnt/).
A noter que des d'enjeux pédagogiques et politico-économiques sont liés à ces standards puisqu'ils véhiculent une certaine "pédagogie", font partie d'un marché de la connaissance et de la formation et peuvent en exclure ceux qui ne les adoptent pas.
Les formats
Actuellement, la mise à disposition de documents électroniques, sauf dans certains cas très spécifiques, passe si ce n'est par l'Internet, pour le moins via des formats liés à l'Internet.
Les documents, lisibles avec un navigateur standard, sont principalement basés sur le format HTML. Ce format peut être "étendu" à l'aide "d'adjuvents" dont les principaux sont les langages de scripts internes (par exemple JavaScript) ou externe (Flash ou applet Java).
Il est important de considérer que, si le navigateur reçoit des documents HTML ceux-ci peuvent être constitués les flux construits à partir de ressources diverses, agrégats de documents enregistrés sous forme de fichiers, d'enregistrements de bases de données ou encore directement produits par des programmes.
Pour prendre en charge une partie de l'information et orchestrer l'ensemble, un langage est proposé XML (extended makup language). Les caractéristiques et avantages de cette approche sont donnés ci-dessous.
Spécificité de XML
XML est un langage de balisage directement issu de SGML, langage mature qui s'est révélé adapté à de nombreux cas, dont il reprend les principales caractéristiques tout en le simplifiant.
En XML, tout document est décrit de façon conceptuelle avec des jeux de caractères simples. Ceci, lié à l'abondance de traducteur XML, fait que les informations codées en XML gardent un statut indépendant d'applications particulières (toutefois, il est possible d'inclure des applications qui évidemment ne profitent pas toujours de cette garantie de pérennité). Le format est largement décrit sur le site du Consortium "World Wide Web".
Les deux alternatives qui sont souvent opposées à XML sont l'utilisation de HTML ou des bases de données.
Pourquoi ne pas directement utiliser HTML?
Principalement parce que ce langage est un langage de description physique ou du moins peu conceptuel. Il n'est pas lié au contenu mais à la façon de le présenter.
Pourquoi ne pas utiliser uniquement des bases de données?
Ce n'est pas incompatible. Un document XML peut être logé dans une base de données. A contrario, une base de donnée peut indexer des documents XML ou encore des appels à des bases de données peuvent s'effectuer à partir d'un document XML. Mais l'approche est différente. XML est une approche globale, par document. Une base de données implique une approche plus locale, par "champs".
Caractéristiques du langage
Un projet XML est développé sur la base d'une DTD (Data Type Description) qui représente une classe de documents. Chaque document devra être conforme à cette DTD. Une approche, liée à des SCHEMA, est en train de se développer. Cette nouvelle approche permet une plus grande précision dans les définitions, par contre l'approche par DTD semble fournir une meilleure technique d'analyse, notamment pour les petits projets.
Les objectifs qui ont servi de base à la
définition de
XML sont les suivants:
- XML doit être largement utilisable sur l'Internet
- XML doit supporter une grande variété d'applications
- XML doit être compatible avec SGML
- Il doit être facile d'écrire des logiciels qui utilisent des documents XML
- Le nombre d'options doit être minimum
- Les documents XML doivent être lisibles
- XML doit être formel et concis (et rapidement disponible!)
- La création d'un document XML doit être facile
- La concision en ce qui concerne le marquage est d'une importance relative
Le problème de l'usabilité directe ou la lisibilité du langage XML par les créateurs de contenu (les enseignants par exemple), reste ouvert. Il fera l'objet de la prochaine Lettre.
Méthode de travail
Le travail se fait à l'aide d'éditeurs généraux ou spécialisés (cf annexe 2) et des outils permettent d'utiliser les documents XML à partir de diverses applications (cf annexe 3).
Un cas pratique
Le projet Ermitage est développé avec cette technique dont la présentation contient plusieurs références utiles (Pour les aspects techniques, voir la page sur ABORD ou la version actuelle de la DTD).
La figure 1 résume les principaux éléments intervenant dans un dispositif basé sur XML.
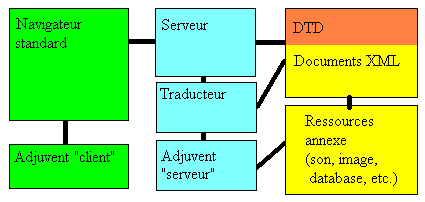
-
la partie client constituée d'un navigateur standard, étendu par des adjuvents (si possible en petit nombre).
-
la partie serveur qui comprend un serveur standard (http) éloigné ou sur le même ordinateur que le client. Ce serveur est étendu par des traducteurs (de XML vers HTML) et d'autres programmes (si possible en petit nombre).
-
Les informations où XML permet à la fois de d'orchestrer l'ensemble des ressources et d'en constituer la partie textuelle.
Pour conclure
Les recommandations pour le développement d'un projet mettant à disposition des ressources pédagogiques de moyennes importances (niveau d'un canton ou d'une région) peuvent être résumées comme suit:- Tenir compte des standards.
- Privilégier une approche document qui est celle qui semble le mieux répondre à l'élaboration de ressources pédagogiques.
- Séparer les trois niveaux: sémantiques et organisationnels, formatage, présentation.
- Utiliser XML pour les contenus textuels et l'orchestration de l'ensemble.
L.-O. Pochon, mars 2002
Annexe 1: Normes et metadata
The ARIADNE Foundation (extrait de: www.ariadne-eu.org) was created to exploit and further develop the results of the ARIADNE and ARIADNE II European Projects, which created tools and methodologies for producing, managing and reusing computer-based pedagogical elements and telematics supported training curricula.
IEEE Learning Technology Standards Committee (LTSC) (extrait de: ltsc.ieee.org/ltsc/) : The mission of IEEE LTSC working groups is to develop technical Standards, Recommended Practices, and Guides for software components, tools, technologies and design methods that facilitate the development, deployment, maintenance and interoperation of computer implementations of education and training components and systems. LTSC has been chartered by the IEEE Computer Society Standards ActivityBoard. Many of the standards developed by LTSC will be advanced as international standards by ISO/IEC JTC1/SC36 - Information Technology for Learning, Education, and Training). Voir aussi: Learning object métadata (LOM) (version juillet 2012, référence ajoutée lors de la mise en ligne de "La Lettre").
IMS Project (extrait de: www.imsproject.org/) : The growth of the Internet and the World Wide Web is transforming teaching and learning at all levels of education, in the workplace, and at home. IMS Global Learning Consortium, Inc. (IMS) is developing and promoting open specifications for facilitating online distributed learning activities such as locating and using educational content, tracking learner progress, reporting learner performance, and exchanging student records between administrative systems. IMS has two key goals:
- Defining the technical specifications for interoperability of applications and services in distributed learning, and
- supporting the incorporation of the IMS specifications into products and services worldwide. IMS endeavors to promote the widespread adoption of specifications that will allow distributed learning environments and content from multiple authors to work together (in technical parlance, "interoperate").
IMS is a global consortium with members from educational, commercial, and government organizations. Funding comes from membership fees, with organizations choosing to join as either Contributing Members or Developers Network Subscribers.
Sharable Content Object Reference Model (SCORM™)
(extrait
de: www.adlnet.org;
www.adlnet.org/Scorm/docs/SCORM_2.pdf) : Is
- A reference model that defines a Web-based learning "content model"
- A set of interrelated technical specifications designed to meet the Department of Defense's high level "-ilities"
- A process to knit together disparate groups and interests
- A bridge from general emerging technologies to commercial implementations
- An evolving document to collect all the "bits and pieces" in one place
Les nouvelles de la formation à distance (thot.cursus.edu): de nombreuses informations dont les plateformes pour développeurs de cours "on-line" (thot.cursus.edu/rubrique.asp?no=12074)
Annexe 2: Editeur XML
Xeena (www.alphaworks.ibm.com/tech/xeena): Editeur XML en Java mis à disposition par IBM.
Merlot (extrait de: www.merlotxml.org) : Merlot is a Java based XML modeling application written to make creating and editing XML files easier. It runs on any Java 2 virtual machine (JDK1.2.2 or JDK1.3). The application is extensible via custom editor plugins that can be added for individual DTD's. (Open source).
XML Spy (extrait de: www.xmlspy.com):
XML Spy 4.2 IDE (integrated development environment) is the industry
leading solution for XML-based applications, making it easy to create
and manage XML documents, stylesheets, and schemas. It is the essential
power tool for XML application developers.
Annexe 3: Outils de base
Le projet XML de Apache (extrait de: xml.apache.org/): The goals of the Apache XML Project are: to provide commercial-quality standards-based XML solutions that are developed in an open and cooperative fashion, to provide feedback to standards bodies (such as IETF and W3C) from an implementation perspective, and to be a focus for XML-related activities within Apache projects
The Apache XML Project currently consists of seven
sub-projects,
each focused on a different aspect of XML:
- Xerces - XML parsers in Java, C++ (with Perl and COM bindings)
- Xalan - XSLT stylesheet processors, in Java and C++
- Cocoon - XML-based web publishing, in Java
- AxKit - XML-based web publishing, in mod_perl
- FOP - XSL formatting objects, in Java
- Xang - Rapid development of dynamic server pages, in JavaScript
- SOAP - Simple Object Access Protocol
- Batik - A Java based toolkit for Scalable Vector Graphics (SVG)
- Crimson - A Java XML parser derived from the Sun Project X Parser.